Lab 10 - Testowanie hipotez cz. 2
Lab 08 - Testowanie hipotez cz. 2
Test chi-kwadrat
Test używany do weryfikacji hipotez dla zmiennych mających rozkład chi-kwadrat np. niezależnych zmiennych nominalnych (rzutów kostką).
W teście tym oraz rozkładzie istotną rolę odgrywa pojęcie stopni
swobody df. Dla zmiennych nominalnych liczba stopni swobody
wynosi M-1 gdzie M jest liczbą niezależnych
zmiennych (np. dla rzutów monetą df=1, dla rzutów kostką
df=5). Wynika to z faktu, że dla losowania M zmiennych,
jeśli wiadomo, że nie wylosowano M-1 możliwych wartości to
wartość wylosowana jest znana (zależna).
Dla zmiennej zliczanej (gdzie określa się liczbę wystąpień poszczególnych wartości zmiennej nominalnej) statystyka testowa ma postać:

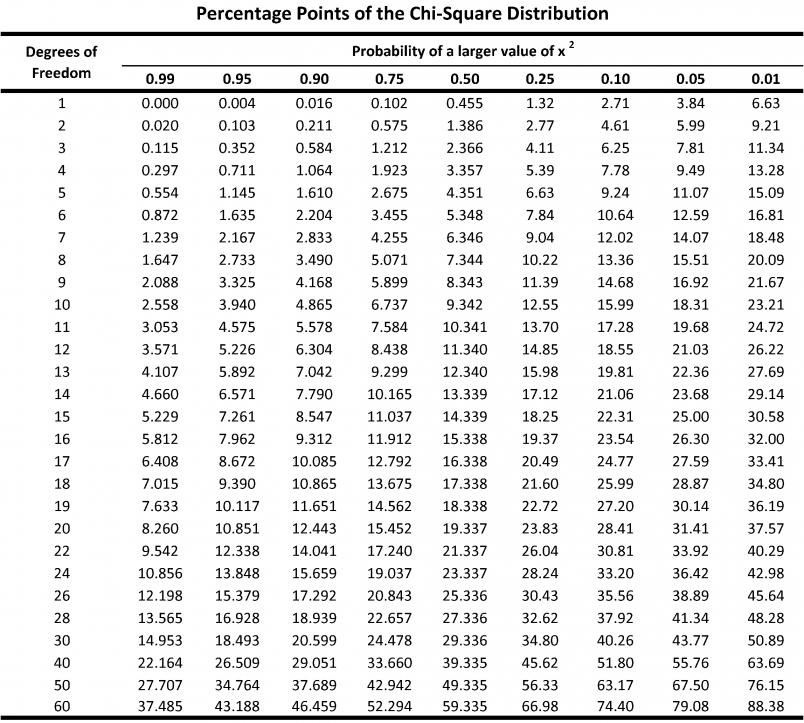
Gdzie Oi jest zaobserwowaną częstością/liczbą wystąpień natomiast Ei jest oczekiwaną częstością/liczbą wystąpień pochodzącą z rozkładu teoretycznego lub z innego rozkładu empirycznego względem którego chcemy przeprowadzić test. Graniczną wartość statystyki dla danego poziomu ufności (ɑ) możemy odczytać z tablic.
{kind=link}
Załóżmy, że badacz na grupie N=60 sprawdzał 3 napoje (A, B, C) napój
A smakował 20 osobom, napój B 25 osobom a napój C 15 osobom. Badacz
założył, że jeśli napoje nie różniły się preferencjami to powinien
uzyskać podobne wyniki we wszystkich grupach (po 20 osób). Statystykę
rozkładu chi kwadrat (chi2), oraz prawdopodobieństwo
testowe (p) danej liczby obserwacji możemy wyznaczyć
również używając funkcji:
from scipy.stats import chisquare
obs = np.array([20, 25, 15]) # wartość obserwowana
exp = np.array([1/3, 1/3, 1/3]) * np.sum(obs) # oczekiwana liczba wystąpień (suma musi być taka jak dla obs!!!)
chi2, p = chisquare(obs, exp)Spróbuj wyznaczyć wartość rozkładu chi kwadrat ręcznie (korzystając z wzoru), a następnie zweryfikować z wynikiem funkcji oraz określić graniczną wartość statystyki dla poziomu istotności ɑ=0.05, Jeśli p<ɑ, jest podstawa do odrzucenia hipotezy H0 o braku istotnej różnicy między preferencjami.
Test chi kwadrat można również wykorzystać do badania niezależności zmiennych. Załóżmy, że mamy tablicę opisującą relację między kolorem włosów a kolorem oczu:
| włosy brązowe | włosy czarne | włosy jasne | włosy rude | Suma | |
|---|---|---|---|---|---|
| oczy brązowe | 438 | 228 | 115 | 16 | 797 |
| oczy szare/zielone | 1387 | 746 | 946 | 53 | 3132 |
| oczy niebieskie | 807 | 189 | 1768 | 47 | 2811 |
| Suma | 2632 | 1163 | 2829 | 116 | 6740 |
eyes_vs_hair = [[438, 228, 115, 16], [1387, 746, 946, 53], [807, 189, 1768, 47]]Jeśli kolor oczu jest niezależny od koloru włosów, to oczekiwana
liczba wystąpień Eij (dla i-tego koloru włosów i j-tego
koloru oczu jest opisana wyrażeniem:

gdzie Si, Sj są sumami i-tej
kolumny i j-tego wiersza, a Stotal liczbą wszystkich
elementów. Wyznacz wszystkie wartości oczekiwanej liczby wystąpień dla
założenia o niezależności obu zmiennych, a następnie oblicz test chi
kwadrat z tabeli, liczba stopni swobody jest iloczynem stopni swobody
dla każdej zmiennej (w kolumnach i w wierszach) i wynosi df = 6 a nie
11. Możesz to zrealizować używając funkcji
chi2_contingency, gdzie tabela będzie zawierać 3 wiersze
odpowiadające kolorom oczu. Sprawdź ile wynosi prawdopodobieństwo
testowe oraz liczba stopni swobody?
Test Anova 1-parametryczny
Test Anova umożliwia sprawdzenie czy istnieje istotna różnica między 2 lub więcej rozkładami statystyki, gdzie zakłada się, że rozkłady są niezależne, normalne i mają zbliżoną wariancję. W testach A/B możliwe było porównanie wyłącznie 2 niezależnych rozkładów.
Załóżmy, że mamy dane o dziennym spożyciu wapnia (w mg/dzień) u grupy kontrolnej oraz u osób wykazujących niską gęstość kości (osteopenia) i osób cierpiących na osteoporozę. Chcemy sprawdzić czy istnieje istotna statystycznie różnica między suplementacją wapnia u osób z normalną gęstością kości, grupą o cechach osteopenii i osób cierpiących na osteoporozę. Zakładamy, że dane zostały pozyskane z danych szpitala dla losowych osób.
| Normalna gęstość | Osteopenia | Osteoporoza |
|---|---|---|
| 1200 | 100 | 890 |
| 1000 | 1100 | 650 |
| 980 | 700 | 110 |
| 900 | 800 | 900 |
| 750 | 500 | 400 |
| 800 | 700 | 350 |
| 850 | 750 | 450 |
| 500 | 850 | 500 |
data = [[1200, 100, 890], [1000, 1100, 650], [980, 700, 110], [900, 800, 900],
[750, 500, 400], [800, 700, 350], [850, 750, 450], [500, 850, 500]]Procedura Anova: 1. Sprawdź hipotezę o normalności rozkładów, oraz sprawdź czy wariancje są zbliżone. do testowania normalności rozkładu możesz wykorzystać funkcję normaltest. Prawdopodobieństwo testowe p>ɑ nie daje podstaw do odrzucenia hipotezy, że rozkład jest normalny.
- Dla serii danych wykonaj test one-way Anova, sprawdzając hipotezę H0, że nie ma istotnych różnic:
from scipy.stats import f_oneway
f_value, p_value = f_oneway(data1, data2, data3)
print(f'F-stat: {f_value}, p-val: {p_value}')- Jeśli prawdopodobieństwo testowe (
p_value) pozwala odrzucić hipotezę zerową, przeprowadź test post-hoc Tukey’a umożliwiający określenie pomiędzy którymi parami różnice są istotne.
from statsmodels.stats.multicomp import pairwise_tukeyhsd
print(pairwise_tukeyhsd(np.concatenate([data1, data2, data3]), np.concatenate([['data1']*len(data1), ['data2']*len(data2), ['data3']*len(data3)])))Zinterpretuj wyniki, i wskaż między którymi z par różnica jest istotna.
Określ moc testu dla par, dla których zaobserwowano istotną różnicę.
Zadanie
Wczytaj dane zawierające wyniki wyborów prezydenckich w Rosji z 2020r.
Wyznacz frekwencję w poszczególnych okręgach oraz procentową liczbę głosów za:
df['frekwencja'] = df['given']/np.maximum(1, df['nominal'])
df['glosow_za'] = df['yes']/np.maximum(1, df['given'])Stosując analizę ANOVA wskaż regiony dla których wynik wyborczy nie różni się istotnie od wyniku uzyskanego w Moskwie. Nazwy pisane cyrylicą możesz przekodować stosując moduł transliterate
Przeanalizuj wyniki częstość głosów za, analizując częstotliwość występowania cyfr na drugim miejscu po przecinku. O ile wartość pierwszego miejsca zależy od preferencji wyborczych, można spodziewać się że prawdopodobieństwo występowania cyfr na drugim miejscu będzie równomierne. Zweryfikuj hipotezę, że obserwowana częstość występowania cyfr jest zgodna z rozkładem równomiernym.
Autorzy: Piotr Kaczmarek i Jakub Tomczyński